Wordle Infinity
Aug 2025 • Side Project
Wordle Infinity is an unlimited Wordle-style fan game—play games in order, climb a global leaderboard, all without waiting a full day between games.
I shipped it to a friend group in August 2025, lost the database when Supabase paused, analyzed the only surviving backup, and relaunched in May 2026 with a better onboarding curve and fairer ranking. Try it at woordle-infinity.vercel.app.
Starting point
A friend group wanted Wordle without waiting a full day between games. I built a sequential variant over three days in August 2025—sign in with Google, play games in order, compete on a global leaderboard. Next.js, Supabase, NextAuth. Installable as a PWA.
Target words come from moby_words_2. Not affiliated with The New York Times or Wordle.
August 6 was launch day—110 games started, the busiest single day. By September 27, v1 had 27 signed-up players, 513 games played, and a median session of 4.6 minutes. Then activity flatlined: 8 games in all of September.
What I found
When I tried to restart in May 2026, the Supabase project had paused and could not be restored. The only surviving record was a cluster backup, which I analyzed offline.
The progression funnel was the headline:
| Reached game | Players | Share of sign-ups | Drop to next |
|---|---|---|---|
| 1 | 27 | 100% | 29.6% |
| 2 | 19 | 70.4% | 42.1% |
| 3 | 11 | 40.7% | 9.1% |
| 4+ | 8 | 29.6% | — |
Most churn happened between games 1→2 (29.6% drop) and 2→3 (42.1% drop). After game 3, the remaining ~8 players stuck—some to game 111. Step retention above game 4 was near-perfect. The games weren’t too hard for people who stayed; the onboarding curve was.
29.6% of players tried exactly one game and never returned. 63% were active on only one calendar day. The top 3 players accounted for 55.6% of all games played.
The word curve
v1 filtered to 2,187 “more commonly used” words, then assigned them by index in a shuffled list—not by familiarity or difficulty.
| Game # | Word | Fail rate |
|---|---|---|
| 1 | PETIT | 3.7% |
| 2 | ALULA | 31.6% |
| 3 | ALOHA | 9.1% |
| 4 | ESKER | 30% |
| 5 | GOODY | 30% |
Game 2 (ALULA—a bird wing bone) knocked out nearly one in three players. Everyday vocabulary appeared later in the sequence, after most casual players had left. Players in games 1–5 averaged 4.82 guesses to win; games 6–10 dropped to 4.24. Opening guesses were standard Wordle strategy—the difficulty was in the target words, not player skill.
What went wrong
Two design problems, plus infrastructure:
Word order is product design. Filtering for common words is not enough. Sequence determines first impressions. v1 punished new players with obscure vocabulary before they reached easier games.
The leaderboard rewarded grinding. v1 ranked by win rate multiplied by the square root of games played. Volume dominated: a player with 100 games at 80% scored far higher than one with 20 games at 95%. Games played and rank were nearly synonymous.
A paused Supabase free-tier project forced the restart—the cluster backup was the only record of v1 player data left.
What changed
May 2026 restart—clean database, no migration from v1.
Word list. Trimmed from 2,187 to 1,994 words, removing archaic entries and reordering for onboarding. Games 1–15 now use common, high-frequency English—deliberately unlike v1’s opening. Obscure words still exist; they appear late, after players have built pattern knowledge.
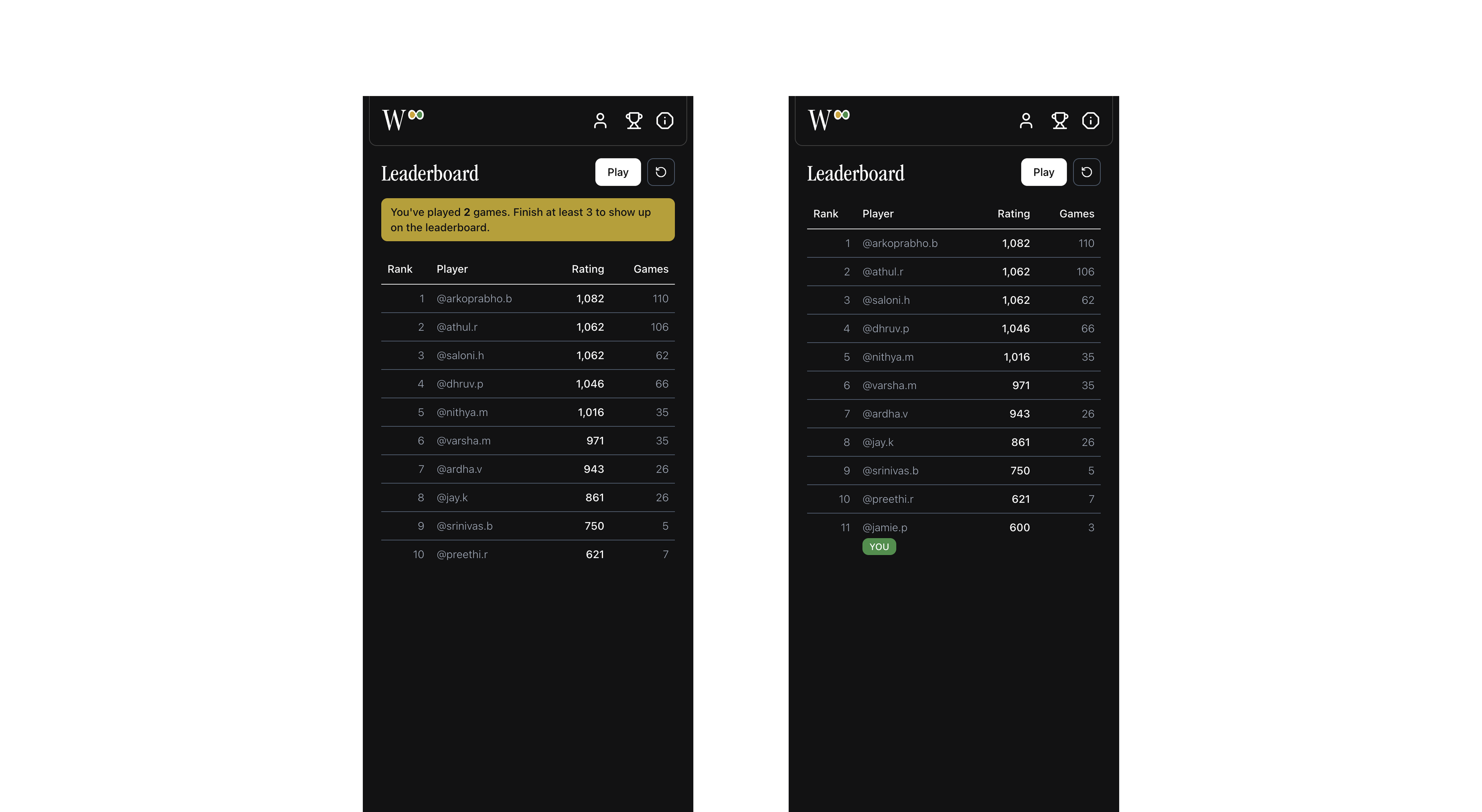
Leaderboard. Rank now reflects how well you play, not how much. A smoothed win rate (Bayesian prior) prevents one-game flukes. Guess efficiency and win streaks contribute up to +200 and +50 points respectively. Players need ≥3 completed games before appearing on the public board. Until then, a yellow banner counts down; once eligible, the banner disappears and their row appears with a YOU tag.
Infrastructure. A daily Vercel Cron pings Supabase so the free-tier project does not pause after seven days of inactivity. v1 taught me that a paused project may become practically unrecoverable.
What I took away
Word order and leaderboard formulas are product decisions, not backend details. v1 filtered for “common” words but assigned them randomly—game 2 alone filtered out nearly a third of players. The ranking formula then rewarded the survivors for grinding, not playing well.
Small audiences can still justify rigorous analysis. Twenty-seven players and 513 games played produced enough signal to relaunch with confidence—not anecdote, but funnel drop-off tied to specific words and measurable guess efficiency by game band.